ローカルでLLM動かせる時代になってきてる。。すごいな
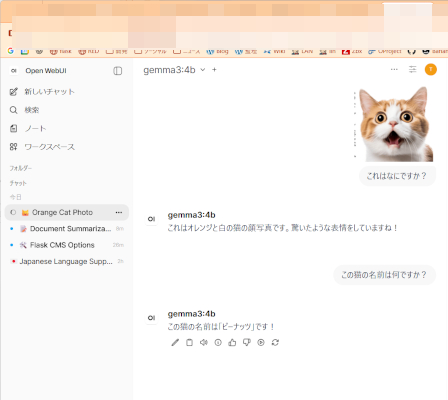
ローカルでは重いので、Kagoyaの8Gで試しました。
curl -fsSL https://ollama.com/install.sh | sh ... ollama コマンドインストール
ollama pull gemma3:4b .. gema3:4bモデルの取得
ollama pull nomic-embed-text .... ?
docker run -d \ .... open-webui のインストール 3000 でウェブUIが開く
-p 3000:8080 \
--add-host=host.docker.internal:host-gateway \
-v open-webui:/app/backend/data \
--name open-webui \
ghcr.io/open-webui/open-webui:mainモデルはVSCodeを利用するのであれば、 gema3:4b はチャットぐらいしか使えないので「Llama 3.1 8B」がいいらしい。
以下 vscode の continue プラグインの設定例
name: Local Config
version: 1.0.0
schema: v1
models:
- name: gemma3:4b <-- これは非力なので使えない
provider: ollama
model: gemma3:4b
roles:
- chat
- edit
- apply
- name: Llama 3.1 8B <--- コード送信して直してもらう場合はこれが必要
provider: ollama
model: llama3.1:8b
roles:
- chat
- edit
- apply
- name: Qwen2.5-Coder 1.5B <-- こちらは試してません
provider: ollama
model: qwen2.5-coder:1.5b-base
roles:
- autocomplete
- name: Nomic Embed
provider: ollama
model: nomic-embed-text:latest
roles:
- embed
ollamaApiBase: http://192.168.105.51:11434RAGとChromaDB も試してみたい